Rapports financiers & bilans
Résultats trimestriels, rapports annuels, déclarations réglementaires — extrayez des tableaux de revenus, bilans et comptes de résultats en feuilles de calcul modifiables.
Déposez un PDF ou une image d'un tableau et extrayez chaque ligne, colonne et cellule fusionnée dans une feuille Excel modifiable. Fonctionne avec les PDFs textuels, les documents scannés, les rapports multipages et les photos de pages imprimées.
0/5 conversions de documents quotidien
Commencez gratuitement • Tous types de documents • Aucune inscription requise
Confidentialité d'abord : Vos images ne sont jamais stockées - traitées instantanément puis supprimées
Glissez-déposez votre PDF ou prenez une photo d'une page imprimée. Choisissez un format de sortie : Excel, CSV, Word, JSON.
Notre IA lit votre PDF et tente d'identifier les structures de tableaux, les en-têtes et les valeurs de cellules — y compris les PDF numérisés sans texte sélectionnable. L'ensemble du document est analysé simultanément afin de préserver le contexte multipage.
Chaque PDF produit sa propre feuille de calcul avec la structure préservée — téléchargement instantané, ou livraison par e-mail sur Free+ et Premium. Premium peut livrer un lot de PDF sous forme d'un seul fichier ZIP.
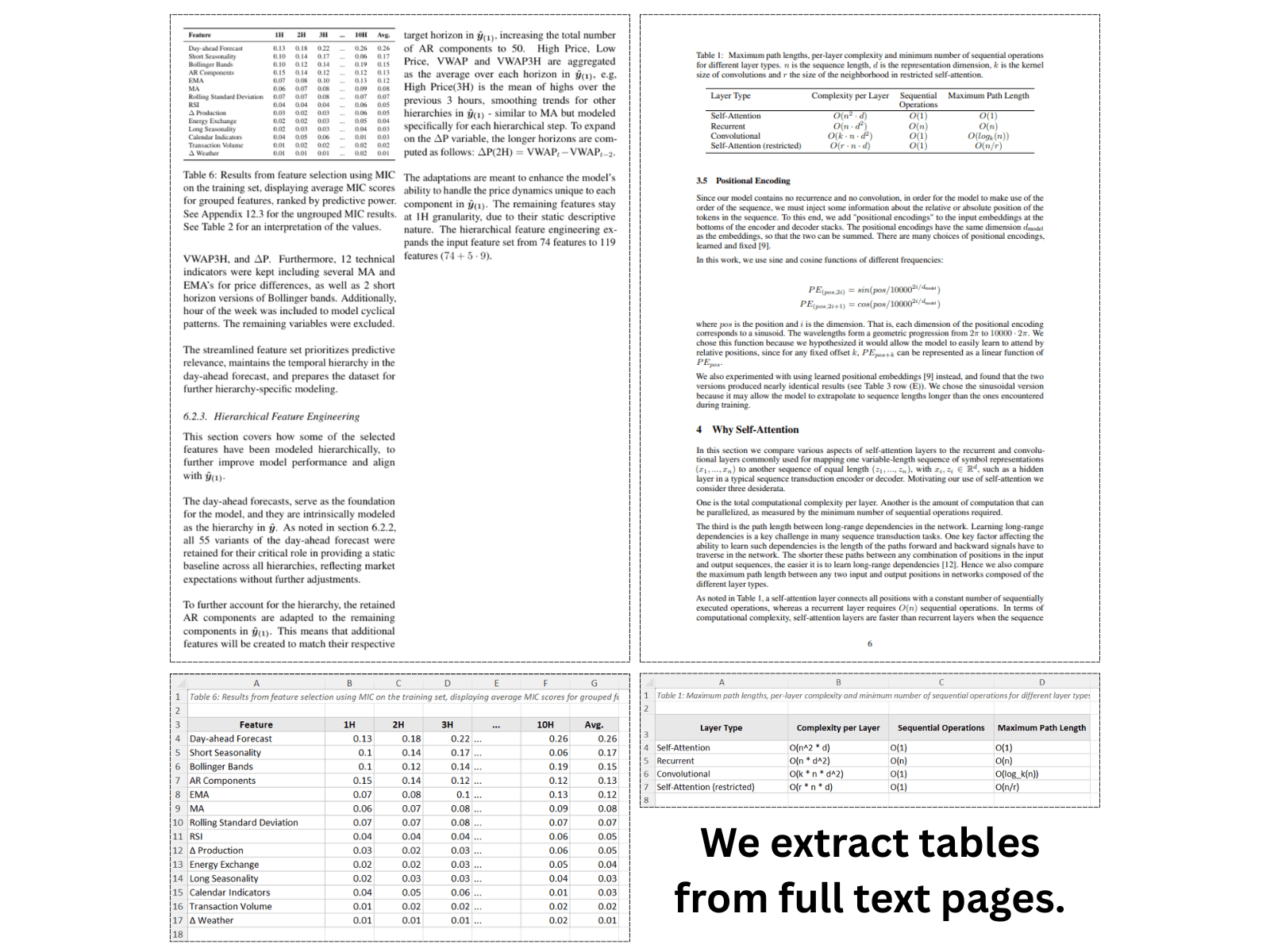
Vrais documents, véritables résultats Excel — exemples en direct qui s'actualisent automatiquement toutes les quelques secondes.
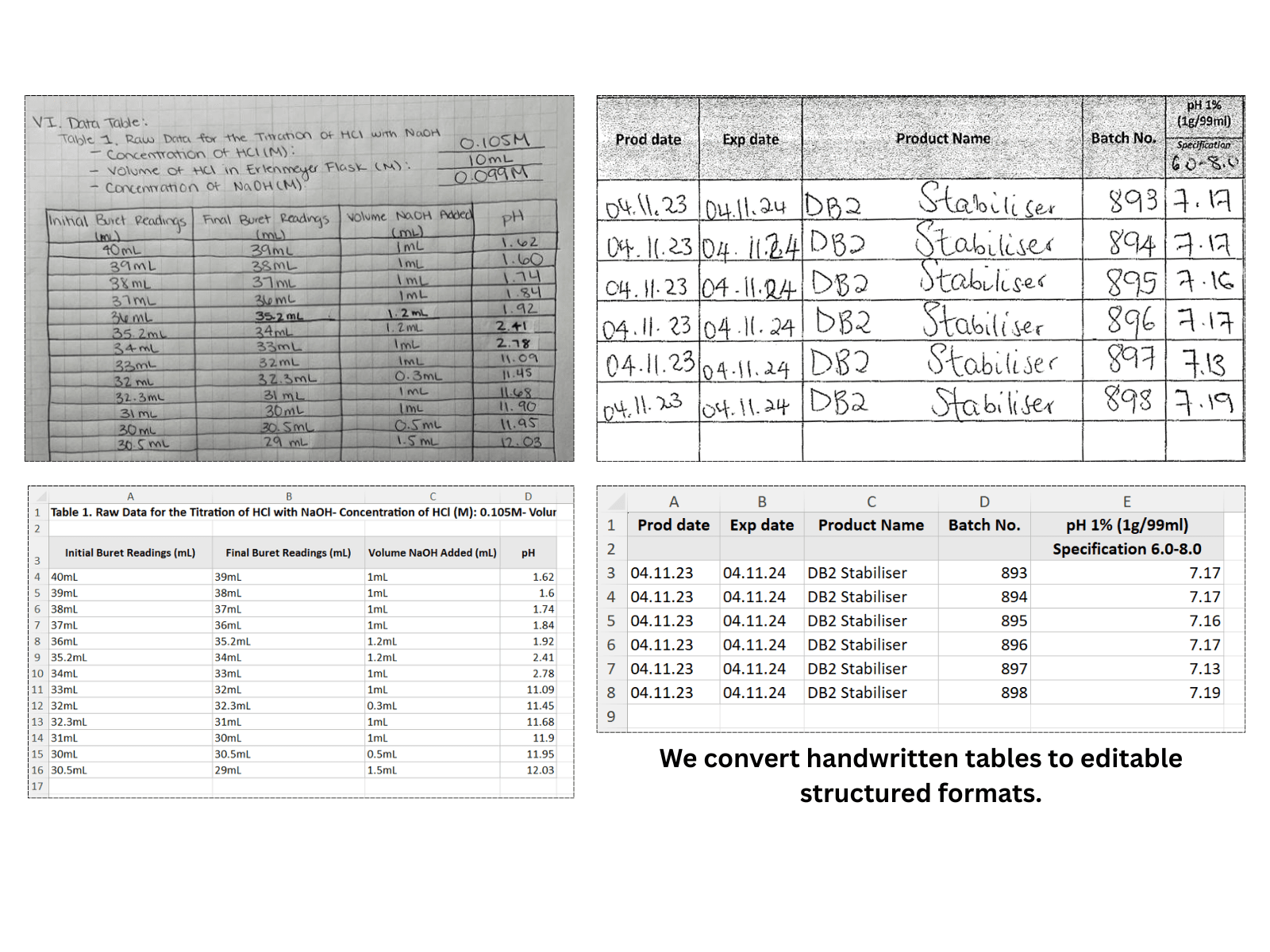
Deux tableaux manuscrits (une photo et un scan) reconstruits cellule par cellule dans des tableaux Excel structurés.
Chaque PDF stocke les tableaux différemment. L'IA de ScanToExcel analyse chaque format — qu'il s'agisse d'une couche de texte que vous ne pouvez pas copier ou d'une image numérisée sans texte sélectionnable.
Résultats trimestriels, rapports annuels, déclarations réglementaires — extrayez des tableaux de revenus, bilans et comptes de résultats en feuilles de calcul modifiables.
Études publiées, résultats d'essais cliniques, données de recensement — extrayez des tableaux statistiques de revues sans transcription manuelle.
Catalogues fournisseurs, PDF de tarifs, fiches techniques — transformez-les en feuilles de calcul triables et filtrables.
Annexes de contrats, calendriers de conformité, tableaux de licences — convertissez des données juridiques structurées en formats exploitables.
Rapports imprimés, documents anciens numérisés en PDF — aucune couche de texte requise. Notre OCR lit l'image et reconstruit le tableau.
Tableaux qui débordent sur plusieurs pages — l'IA analyse le PDF entier ensemble pour interpréter les données qui s'étendent sur plusieurs pages.
Analyse IA
Sortie & intégration
L'IA lit chaque PDF et tente d'identifier ces éléments de tableau.
Les PDF stockent le texte sous forme de caractères positionnés individuellement — il n'y a ni cellules, ni colonnes, ni lignes dans le format de fichier. Lorsque vous copiez-collez un tableau depuis un PDF, l'alignement des colonnes se brise car la structure n'existe que visuellement.
Les PDF numérisés sont encore plus difficiles : ils ne contiennent qu'une image plate sans aucune couche de texte. Le copier-coller traditionnel ne renvoie rien.
Solution
L'IA de ScanToExcel lit la disposition visuelle de votre PDF et réassigne les caractères positionnés dans des lignes et colonnes structurées — vous donnant une feuille de calcul modifiable au lieu de texte brouillé.
Obtenez les résultats les plus précis de vos conversions de tableaux PDF.
Utilisez le PDF original si possible
Les PDF textuels (où vous pouvez sélectionner du texte) s'extraient plus rapidement et avec plus de précision que les images numérisées.
Évitez les scans basse résolution
Lors de la numérisation d'un document imprimé, utilisez au moins 200 DPI. Une résolution plus élevée signifie une meilleure précision OCR pour les petits textes et chiffres.
Gardez les pages droites
Les scans inclinés ou tournés réduisent la précision. Alignez les pages avant la numérisation ou prenez des photos bien de face.
Un sujet de tableau par envoi
Si un PDF contient des tableaux sans rapport entre eux, l'IA les traite séparément. Regrouper des documents similaires en lot améliore votre flux de travail.
Vérifiez les cellules fusionnées en sortie
Les fusions complexes (sur 3+ lignes et colonnes) sont les plus difficiles à reconstruire. Vérifiez ces cellules dans votre feuille de calcul téléchargée.
Utilisez CSV pour les imports en base de données
Si votre objectif est de charger des données dans une base de données ou un outil BI, choisissez CSV ou JSON au lieu d'Excel pour une intégration plus propre.
Tous les plans incluent tous les types de documents et formats d'entrée. Free, Free+ et Premium partagent le même modèle d'IA — les différences concernent le volume, la taille des lots, la taille des fichiers, la vitesse et la livraison.
Parfait pour une utilisation occasionnelle. Aucun compte requis.
Lots plus grands et livraison par e-mail.
Pour les utilisateurs intensifs qui ont besoin d'un débit maximal.
Déposez votre PDF ou image de tableau et obtenez un fichier Excel propre et modifiable en quelques secondes — sans inscription, sans logiciel, rien n'est stocké.
Extraire les tableaux PDF maintenant