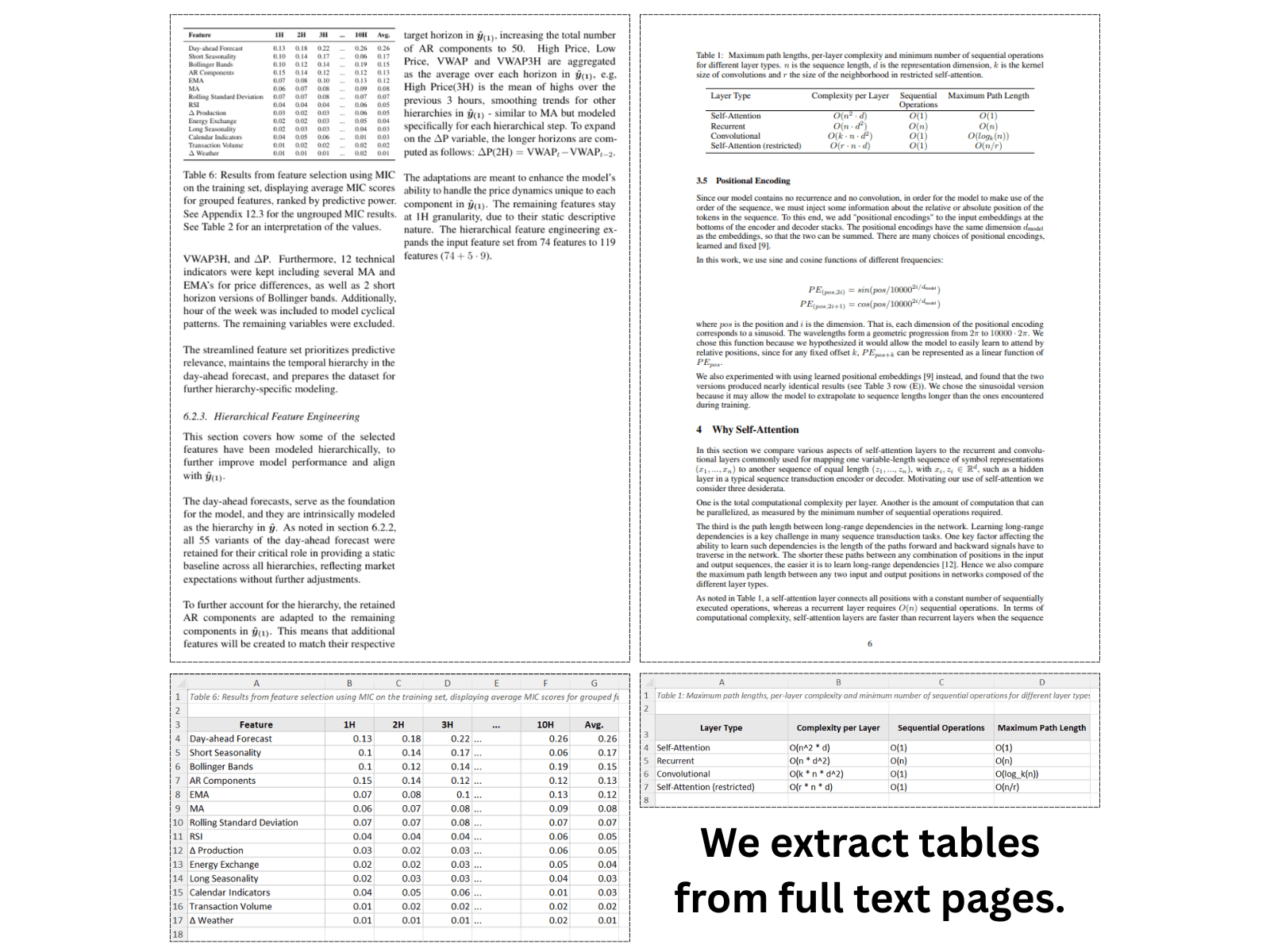
Relatórios financeiros e balanços
Resultados trimestrais, relatórios anuais, declarações regulatórias — extraia tabelas de receitas, balanços e demonstrações de resultados em planilhas editáveis.
Solte um PDF ou imagem de uma tabela e extraia cada linha, coluna e célula mesclada para uma planilha Excel editável. Funciona com PDFs com texto, documentos digitalizados, relatórios multipágina e fotos de páginas impressas.
0/5 conversões de documento diária
Comece grátis instantaneamente • Todos os tipos de documento • Sem registo necessário
Privacidade em Primeiro: As suas imagens nunca são armazenadas - processadas instantaneamente e descartadas
Arraste e solte seu PDF ou tire uma foto de uma página impressa. Escolha um formato de saída: Excel, CSV, Word, JSON.
Nossa IA lê seu PDF e tenta identificar estruturas de tabelas, cabeçalhos e valores de células — incluindo PDFs digitalizados sem texto selecionável. O documento inteiro é analisado em conjunto para preservar o contexto de várias páginas.
Cada PDF produz sua própria planilha com a estrutura preservada — download instantâneo, ou entrega por e-mail no Free+ e Premium. Premium pode entregar um lote de PDFs como um único arquivo ZIP.
Documentos reais, saída real de Excel — exemplos em direto que mudam automaticamente a cada poucos segundos.
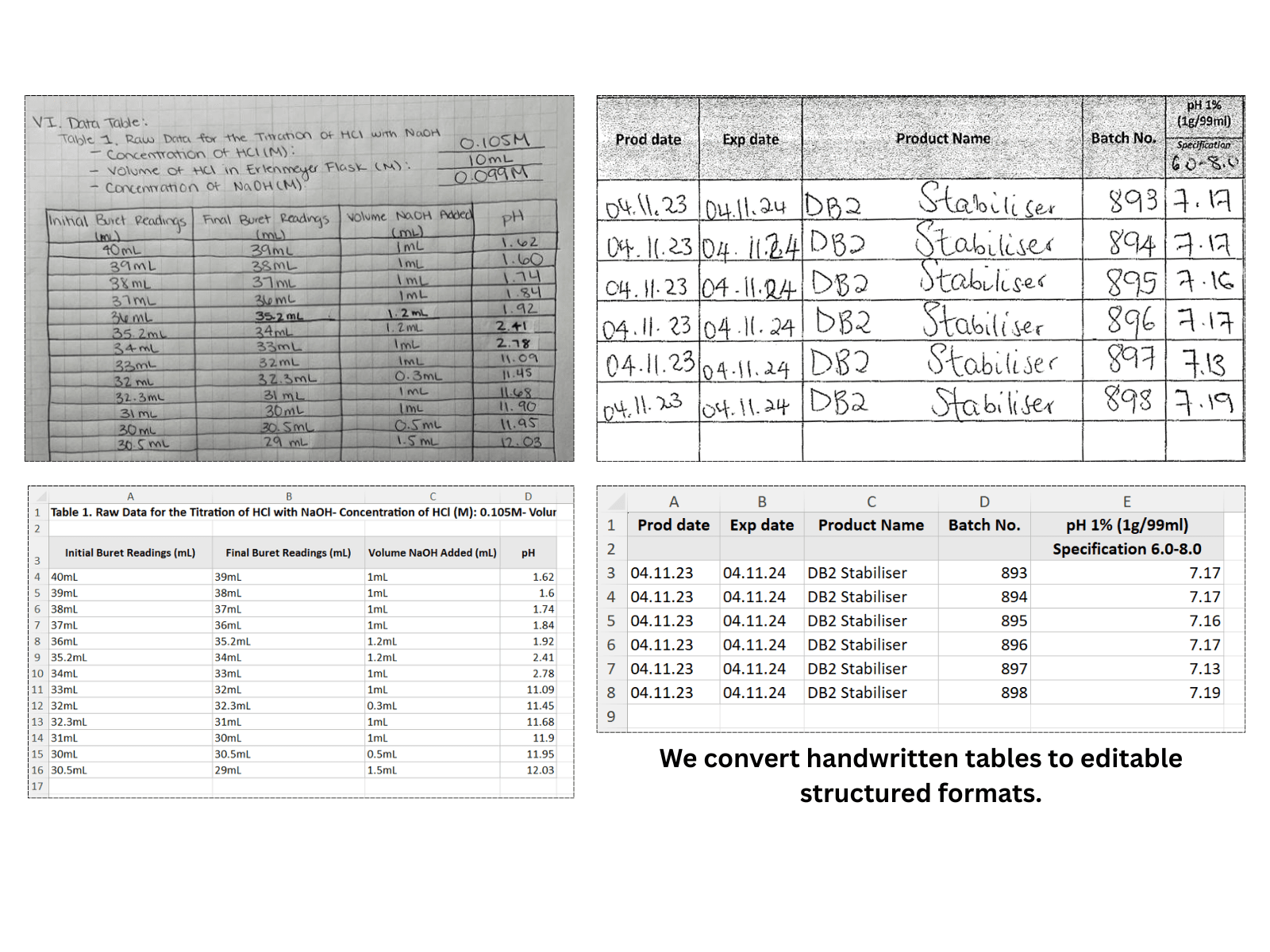
Duas tabelas manuscritas (uma foto e uma digitalização) reconstruídas célula por célula em tabelas Excel estruturadas.
Cada PDF armazena tabelas de forma diferente. A IA do ScanToExcel analisa cada formato — seja uma camada de texto que você não consegue copiar ou uma imagem digitalizada sem texto selecionável.
Resultados trimestrais, relatórios anuais, declarações regulatórias — extraia tabelas de receitas, balanços e demonstrações de resultados em planilhas editáveis.
Estudos publicados, resultados de ensaios clínicos, dados censitários — extraia tabelas estatísticas de periódicos sem transcrição manual.
Catálogos de fornecedores, PDFs de preços, fichas técnicas — transforme-os em planilhas classificáveis e filtráveis.
Anexos de contratos, cronogramas de conformidade, tabelas de licenças — converta dados jurídicos estruturados em formatos utilizáveis.
Relatórios impressos, documentos antigos digitalizados em PDF — nenhuma camada de texto necessária. Nosso OCR lê a imagem e reconstrói a tabela.
Tabelas que continuam em várias páginas — a IA analisa o PDF completo em conjunto para interpretar dados que se estendem por várias páginas.
Análise com IA
Saída e integração
A IA lê cada PDF e tenta identificar estes elementos de tabela.
PDFs armazenam texto como caracteres posicionados individualmente — não há células, colunas ou linhas no formato de arquivo. Ao copiar e colar uma tabela de um PDF, o alinhamento das colunas quebra porque a estrutura só existe visualmente.
PDFs digitalizados são ainda mais difíceis: contêm apenas uma imagem plana sem camada de texto. O copiar e colar tradicional não retorna nada.
Solution
A IA do ScanToExcel lê o layout visual do seu PDF e mapeia caracteres posicionados de volta em linhas e colunas estruturadas — dando a você uma planilha editável em vez de texto embaralhado.
Obtenha os resultados mais precisos das suas conversões de tabelas PDF.
Use o PDF original quando possível
PDFs baseados em texto (onde você pode selecionar texto) são extraídos mais rápido e com maior precisão do que imagens digitalizadas.
Evite digitalizações de baixa resolução
Ao digitalizar um documento impresso, use pelo menos 200 DPI. Maior resolução significa melhor precisão de OCR para texto pequeno e números.
Mantenha as páginas retas
Digitalizações rotacionadas ou inclinadas reduzem a precisão. Alinhe as páginas antes de digitalizar ou tire fotos de frente.
Um tema de tabela por upload
Se um PDF contém tabelas não relacionadas, a IA as processa separadamente. Agrupar documentos semelhantes em lote melhora seu fluxo de trabalho.
Verifique células mescladas na saída
Mesclagens complexas (abrangendo 3+ linhas e colunas) são as mais difíceis de reconstruir. Verifique essas células na planilha baixada.
Use CSV para importações em bancos de dados
Se seu objetivo é carregar dados em um banco de dados ou ferramenta de BI, escolha CSV ou JSON em vez de Excel para uma integração mais limpa.
Todos os planos incluem todos os tipos de documento e formatos de entrada. Free, Free+ e Premium partilham o mesmo modelo de IA — as diferenças são volume, tamanho do lote, tamanho do ficheiro, velocidade e entrega.
Ideal para uso ocasional. Sem conta necessária.
Lotes maiores e entrega por email.
Para utilizadores avançados que precisam do máximo desempenho.
Solte seu PDF ou imagem de tabela e receba um arquivo Excel limpo e editável em segundos — sem cadastro, sem software, nada armazenado.
Extrair tabelas PDF agora