Finanzberichte & Geschäftsberichte
Quartalsberichte, SEC-Filings, Jahresberichte — extrahieren Sie Umsatztabellen, Bilanzen und Gewinn- und Verlustrechnungen in bearbeitbare Tabellenkalkulationen.
Legen Sie ein PDF oder ein Bild einer Tabelle ab und holen Sie sich jede Zeile, Spalte und verbundene Zelle in eine bearbeitbare Excel-Tabelle. Funktioniert mit textbasierten PDFs, gescannten Dokumenten, mehrseitigen Berichten und Handyfotos gedruckter Seiten.
0/5 tägliche Dokumentenkonvertierungen
Sofort kostenlos starten • Alle Dokumenttypen • Keine Anmeldung erforderlich
Datenschutz zuerst: Ihre Bilder werden nie gespeichert - sofort verarbeitet und gelöscht
Ziehen Sie Ihr PDF per Drag & Drop oder fotografieren Sie eine gedruckte Seite. Wählen Sie ein Ausgabeformat: Excel, CSV, Word, JSON.
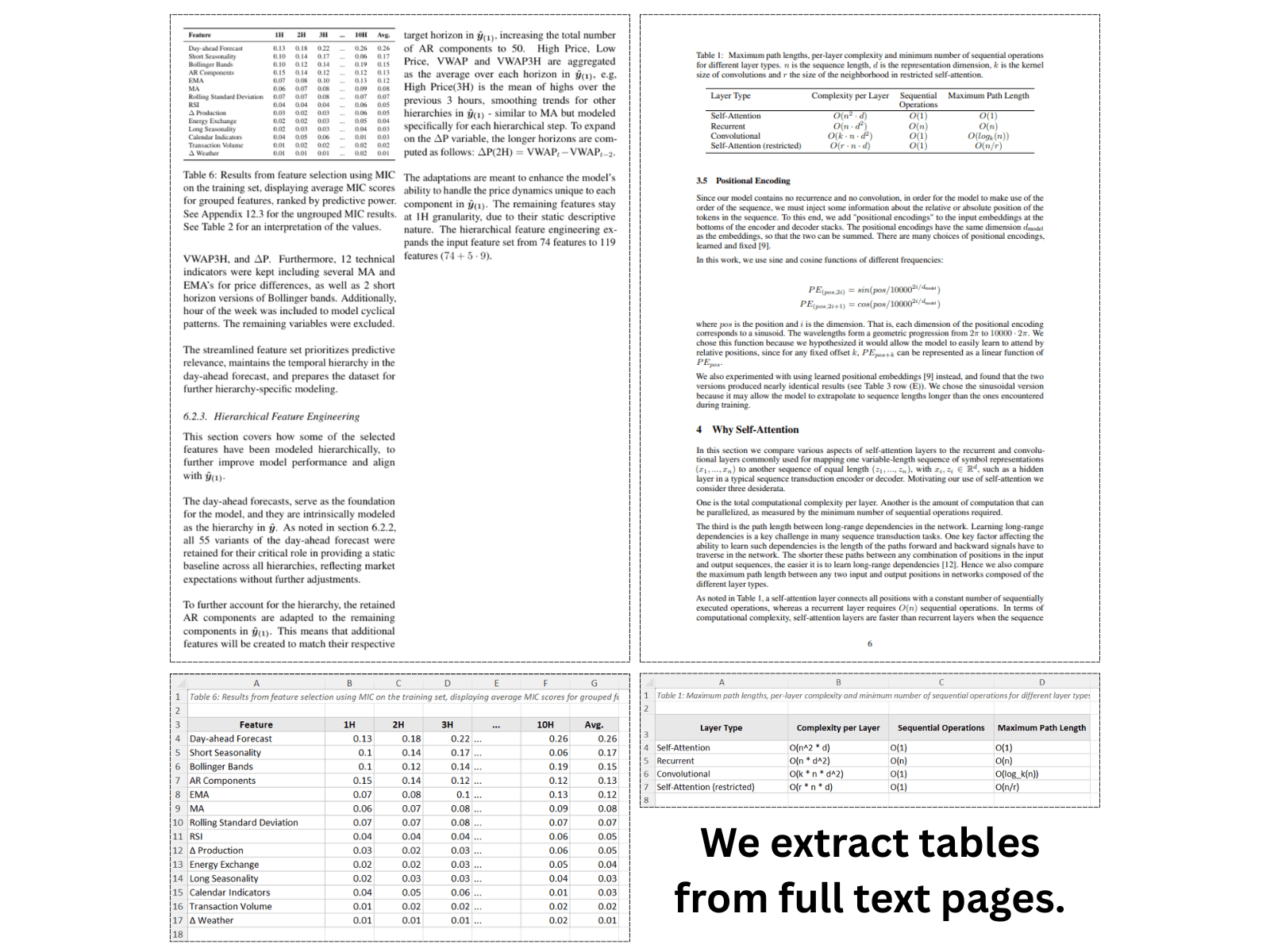
Unsere KI liest Ihr PDF und versucht, Tabellenstrukturen, Kopfzeilen und Zellwerte zu identifizieren — auch bei gescannten PDFs ohne markierbaren Text. Das gesamte Dokument wird zusammen analysiert, sodass der mehrseitige Kontext erhalten bleibt.
Jedes PDF erzeugt eine eigene Tabelle mit erhaltener Struktur — sofortiger Download oder Zustellung per E-Mail bei Free+ und Premium. Premium kann einen Stapel von PDFs als einzelne ZIP-Datei liefern.
Echte Dokumente, echte Excel-Ausgabe — Live-Beispiele, alle paar Sekunden automatisch aktualisiert.
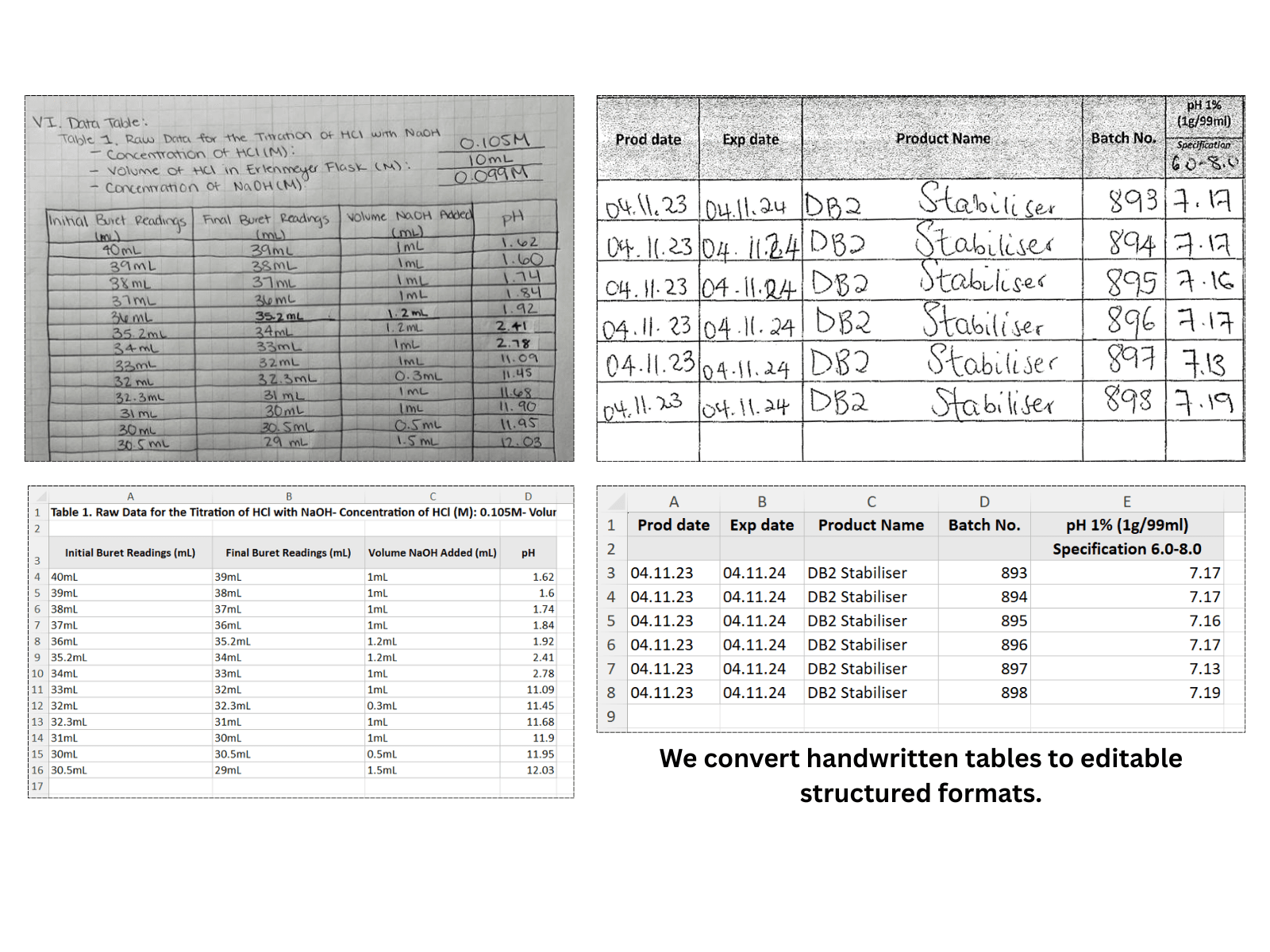
Zwei handschriftliche Tabellen (ein Foto und eine Scan) zelle für zelle in strukturierte Excel-Tabellen rekonstruiert.
Jedes PDF speichert Tabellen anders. ScanToExcels KI analysiert jedes Format — ob es sich um eine Textebene handelt, die Sie nicht kopieren können, oder um ein gescanntes Bild ohne markierbaren Text.
Quartalsberichte, SEC-Filings, Jahresberichte — extrahieren Sie Umsatztabellen, Bilanzen und Gewinn- und Verlustrechnungen in bearbeitbare Tabellenkalkulationen.
Veröffentlichte Studien, klinische Studienergebnisse, Zensusdaten — ziehen Sie statistische Tabellen aus Fachzeitschriften ohne manuelles Abschreiben.
Lieferantenkataloge, Preis-PDFs, Produktdatenblätter — verwandeln Sie sie in sortierbare, filterbare Tabellenkalkulationen.
Vertragsanlagen, Compliance-Pläne, Lizenztabellen — konvertieren Sie strukturierte Rechtsdaten in nutzbare Formate.
Gedruckte Berichte, Altdokumente gescannt zu PDF — keine Textebene erforderlich. Unsere OCR liest das Bild und rekonstruiert die Tabelle.
Tabellen, die über Seiten hinausgehen — die KI analysiert das gesamte PDF zusammen, um Daten zu interpretieren, die sich über mehrere Seiten erstrecken.
KI-Analyse
Ausgabe & Integration
Die KI liest jedes PDF und versucht, diese Tabellenelemente zu identifizieren.
PDFs speichern Text als einzeln positionierte Zeichen — es gibt keine Zellen, keine Spalten, keine Zeilen im Dateiformat. Beim Kopieren einer Tabelle aus einem PDF wird die Spaltenausrichtung zerstört, weil die Struktur nur visuell existiert.
Gescannte PDFs sind noch schwieriger: Sie enthalten nur ein flaches Bild ohne Textebene. Herkömmliches Kopieren und Einfügen liefert nichts.
Solution
ScanToExcels KI liest das visuelle Layout Ihres PDFs und ordnet positionierte Zeichen wieder in strukturierte Zeilen und Spalten ein — für eine bearbeitbare Tabellenkalkulation statt durcheinander gewürfeltem Text.
Erzielen Sie die genauesten Ergebnisse bei Ihren PDF-Tabellenkonvertierungen.
Verwenden Sie das Original-PDF wenn möglich
Textbasierte PDFs (in denen Sie Text markieren können) werden schneller und genauer extrahiert als gescannte Bilder.
Vermeiden Sie niedrig aufgelöste Scans
Beim Scannen eines gedruckten Dokuments verwenden Sie mindestens 200 DPI. Höhere Auflösung bedeutet bessere OCR-Genauigkeit bei kleinem Text und Zahlen.
Seiten gerade halten
Gedrehte oder schiefe Scans verringern die Genauigkeit. Richten Sie Seiten vor dem Scannen aus oder fotografieren Sie von oben.
Ein Tabellenthema pro Upload
Wenn ein PDF unzusammenhängende Tabellen enthält, verarbeitet die KI diese separat. Das Gruppieren ähnlicher Dokumente in einem Stapel verbessert aber Ihren Arbeitsablauf.
Verbundene Zellen in der Ausgabe prüfen
Komplexe Verbindungen (über 3+ Zeilen und Spalten) sind am schwierigsten zu rekonstruieren. Überprüfen Sie diese Zellen in Ihrer heruntergeladenen Tabelle.
CSV für Datenbankimporte verwenden
Wenn Ihr Ziel der Import in eine Datenbank oder ein BI-Tool ist, wählen Sie CSV oder JSON statt Excel für eine sauberere Integration.
Alle Tarife unterstützen jeden Dokumenttyp und jedes Eingabeformat. Free, Free+ und Premium nutzen dasselbe KI-Modell — Unterschiede betreffen Volumen, Stapelgröße, Dateigröße, Geschwindigkeit und Auslieferung.
Perfekt für gelegentliche Nutzung. Kein Konto nötig.
Größere Stapel und E-Mail-Versand.
Für Power-User, die maximalen Durchsatz brauchen.
Legen Sie Ihr PDF oder Bild einer Tabelle ab und erhalten Sie in Sekunden eine saubere, bearbeitbare Excel-Datei — ohne Anmeldung, ohne Software, ohne Speicherung.
PDF-Tabellen jetzt extrahieren